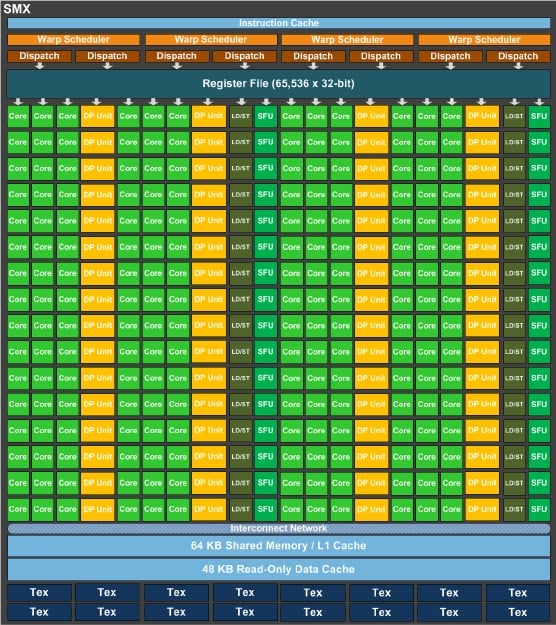
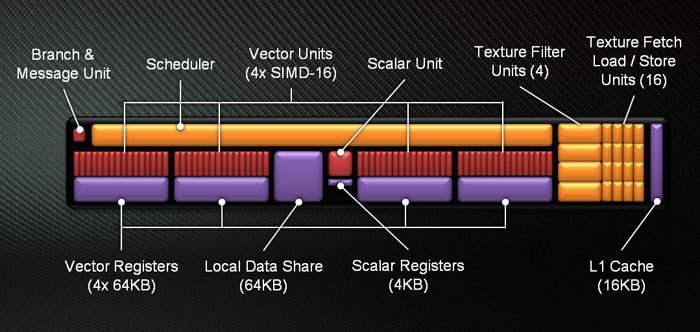
Recently, I had the quite pleasant opportunity to be granted with the Radeon R9 Nano GPU card. This card features the Fiji GPU and as such it seems to be a compute beast as it features 4096 shader units and HBM memory with bandwidth reaching to 512GB/sec. If one considers the card's remarkably small size and low power consumption, this card proves to be a great and efficient compute device for handling parallel compute tasks via OpenCL (or HIP, but more on this on a later post).
One of the first experiments I tried on it was the mixbench microbenchmark tool, of course. Expressing the execution results via gnuplot in the memory bandwidth/compute throughput plane is depicted here:
 |
| AMD R9 Nano GPU card |
One of the first experiments I tried on it was the mixbench microbenchmark tool, of course. Expressing the execution results via gnuplot in the memory bandwidth/compute throughput plane is depicted here:
 |
| mixbench-ocl-ro as executed on the R9 Nano |
For anyone interested in trying mixbench on their CUDA/OpenCL/HIP GPU please follow the link to github:
Acknowledgement: I would like to greatly thank the Radeon Open Compute department of AMD for kindly supplying the Radeon R9 Nano GPU card for the support of our research.