
Link

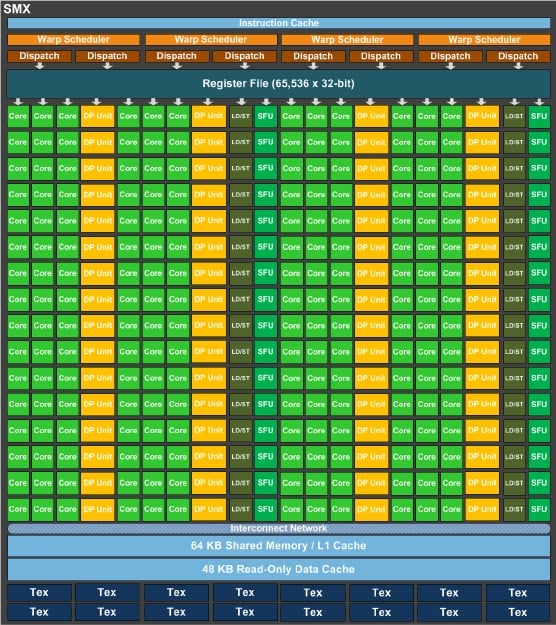

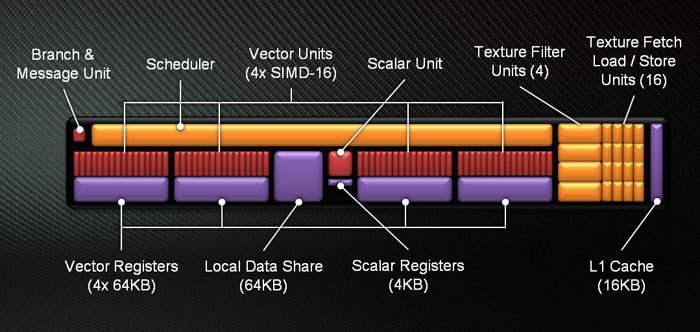
Platform: AMD Accelerated Parallel Processing
Device: Kalindi
Driver version : 1214.3 (VM) (Linux x64)
Compute units : 2
Global memory bandwidth (GBPS)
float : 6.60
float2 : 6.71
float4 : 6.45
float8 : 3.51
float16 : 1.83
Single-precision compute (GFLOPS)
float : 100.63
float2 : 101.26
float4 : 100.94
float8 : 100.32
float16 : 99.08
Double-precision compute (GFLOPS)
double : 6.35
double2 : 6.37
double4 : 6.36
double8 : 6.34
double16 : 6.32
Integer compute (GIOPS)
int : 20.33
int2 : 20.39
int4 : 20.36
int8 : 20.33
int16 : 20.32
Transfer bandwidth (GBPS)
enqueueWriteBuffer : 1.80
enqueueReadBuffer : 1.98
enqueueMapBuffer(for read) : 84.42
memcpy from mapped ptr : 1.81
enqueueUnmap(after write) : 54.32
memcpy to mapped ptr : 1.87
Kernel launch latency : 138.08 us
Device: AMD A6-1450 APU with Radeon(TM) HD Graphics
Driver version : 1214.3 (sse2,avx) (Linux x64)
Compute units : 4
Global memory bandwidth (GBPS)
float : 1.97
float2 : 2.51
float4 : 1.95
float8 : 2.79
float16 : 3.54
Single-precision compute (GFLOPS)
float : 1.30
float2 : 2.50
float4 : 5.01
float8 : 9.21
float16 : 1.07
Double-precision compute (GFLOPS)
double : 0.62
double2 : 1.35
double4 : 2.56
double8 : 6.27
double16 : 2.44
Integer compute (GIOPS)
int : 1.60
int2 : 1.22
int4 : 4.70
int8 : 8.08
int16 : 7.91
Transfer bandwidth (GBPS)
enqueueWriteBuffer : 2.67
enqueueReadBuffer : 2.03
enqueueMapBuffer(for read) : 13489.22
memcpy from mapped ptr : 2.02
enqueueUnmap(after write) : 26446.84
memcpy to mapped ptr : 2.03
Kernel launch latency : 32.74 us
