GPUs require a vast number of threads per kernel invocation in order to utilize all execution units. As a first thought one should spawn at least the same number of threads as the number of available shader units (or CUDA cores or Processor Elements). However, this is not enough. The type of scheduling should be taken into account. Scheduling in Compute Units is done by multiple schedulers which in effect restricts the group of shader units in which a thread can execute. For instance the Fermi SMs consist of 32 shader units but at least 64 threads are required because 2 schedulers are evident in which the first can schedule threads only on the first group of 16 shader units and the other on the rest group. Thus a greater number of threads is required. What about the rest GPUs? What is the minimum threading required in order to enable all shader units? The answer lies on schedulers of compute units for each GPU architecture.
NVidia Fermi GPUs

Each SM (Compute Unit) consists of 2 schedulers. Each scheduler handles 32 threads (WARP size), thus 2x32=64 threads are the minimum required per SM. For instance a GTX480 with 15 CUs requires at least 960 active threads.
NVidia Kepler GPUs
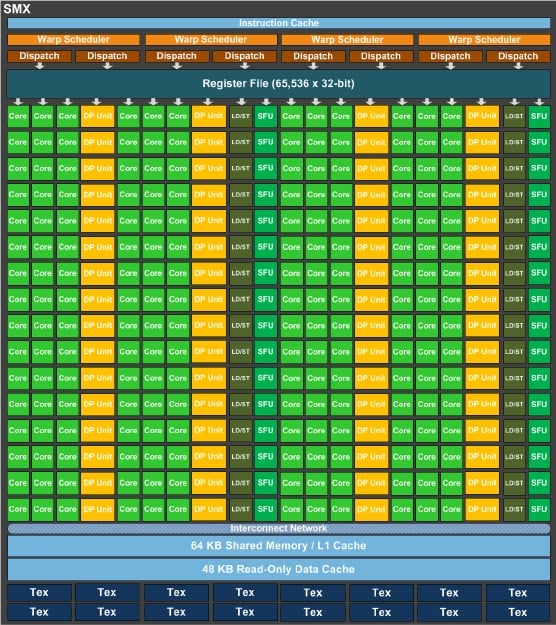
Each SM (Compute Unit) consists of 4 schedulers. Each scheduler handles 32 threads (WARP size), thus 4x32=128 threads are the minimum requirement per SM. A GTX660 with 8 CUs requires at least 1024 active threads.
In addition, more independent instructions are required in the instruction stream (instruction level parallelism) in order to utilize the extra 64 shaders of each CU (192 in total).
NVidia Maxwell GPUs

Same as Kepler. A GTX660 with 8 CUs requires at least 1024 active threads. A GTX980 with 16 CUs requires 2048 active threads.
The requirement for instruction independency does not apply here (only 128 threads per CU).
AMD GCN GPUs
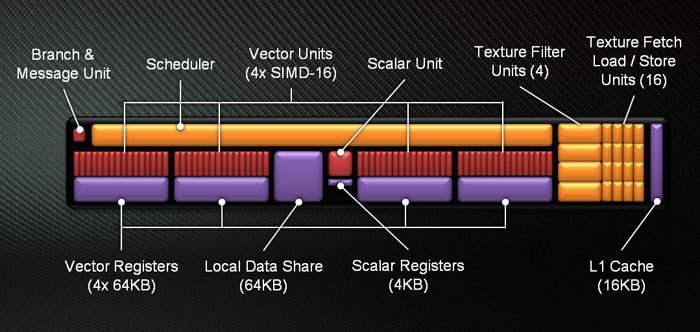
Regarding the AMD GCN units the requirement is more evident. This is because each scheduler handles threads in four groups, one for each SIMD unit. This is like having 4 schedulers per CU. Furthermore the unit of thread execution is done per 64 threads instead of 32. Therefore each CU requires the least of 4x64=256 threads. For instance a R9-280X with 32 CUs require a vast amount of 8192 threads! This fact justifies the reason for which in many research papers the AMD GPUs fail to stand against NVidia GPUs for small problem sizes where the amount of active threads is not enough.
No comments:
Post a Comment