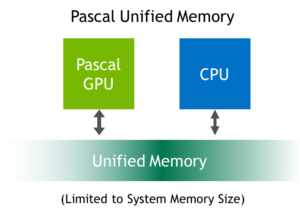
The most impressive feature I found on as advertised is the unified memory support. In CUDA 6 and CC3.0 & CC3.5 devices (Kepler architecture) this term had been first introduced. But it didn't actually provide any real benefits at the time other than programming laziness. In particular, the run-time took care of moving the whole data to/from the GPU memory whenever it was used on either the host or GPU. The GP100 memory unification seems far more complete as according to specifications it seems to take memory unification to the next level. It supports data migration at the granularity of memory page! This means that programmer is able to "see" the whole system memory and the run-time takes care of which memory page should be moved at the time it is actually needed. This is a great feature! It allows porting CPU programs to CUDA without caring which data will actually be accessed.
For instance, imagine having a huge tree or graph structure and and you have a GPU kernel that needs to access just a few nodes on it without knowing which beforehand. Using the Kepler memory unification feature would require copying the whole structure from the host to GPU memory which could potentially cannibalize performance. The Pascal memory unification would actually copy only the memory pages residing on the accessed nodes, instead. This releases programmer from a great pain and that's why I think this is the most exciting feature.
For instance, imagine having a huge tree or graph structure and and you have a GPU kernel that needs to access just a few nodes on it without knowing which beforehand. Using the Kepler memory unification feature would require copying the whole structure from the host to GPU memory which could potentially cannibalize performance. The Pascal memory unification would actually copy only the memory pages residing on the accessed nodes, instead. This releases programmer from a great pain and that's why I think this is the most exciting feature.
I really hope this feature will be eventually supported on consumer GPU variants and stays not just an HPC feature for in Tesla products. I also hope that AMD will also support such a feature in its emerging ROCm platform.
Resources:
No comments:
Post a Comment